Metrics
Training Dashboard
Model performance across training rounds with iterative improvements.
—
Mean IoU
Best
—
Mean Dice
Best
—
Pixel Accuracy
Best
—
Epochs Trained
Per Round
📈 Round-over-Round Improvement
Per-Class IoU — Round 1 vs Round 2
Loss Curves — Both Rounds
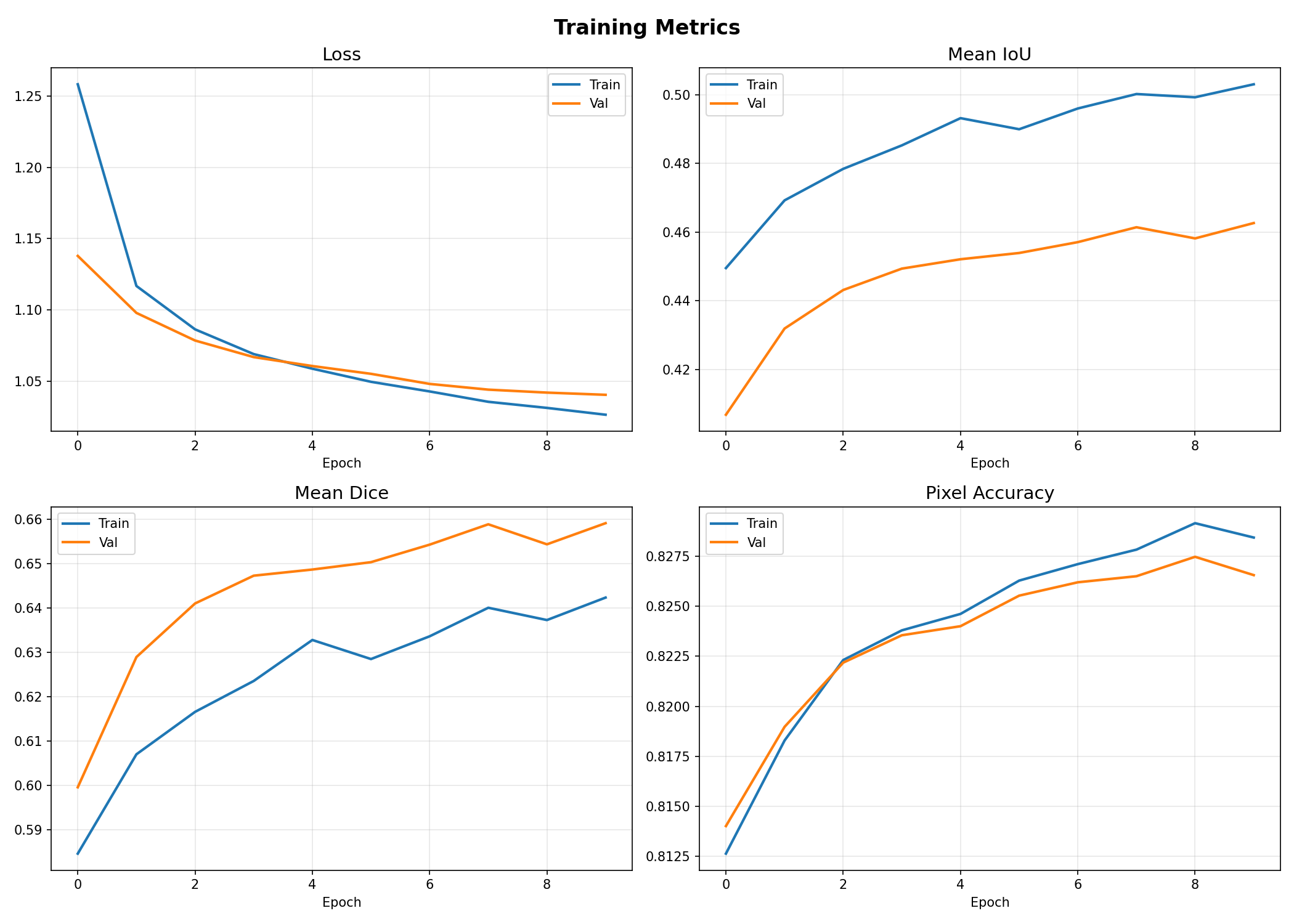
📊 Round 1 — Training Plots
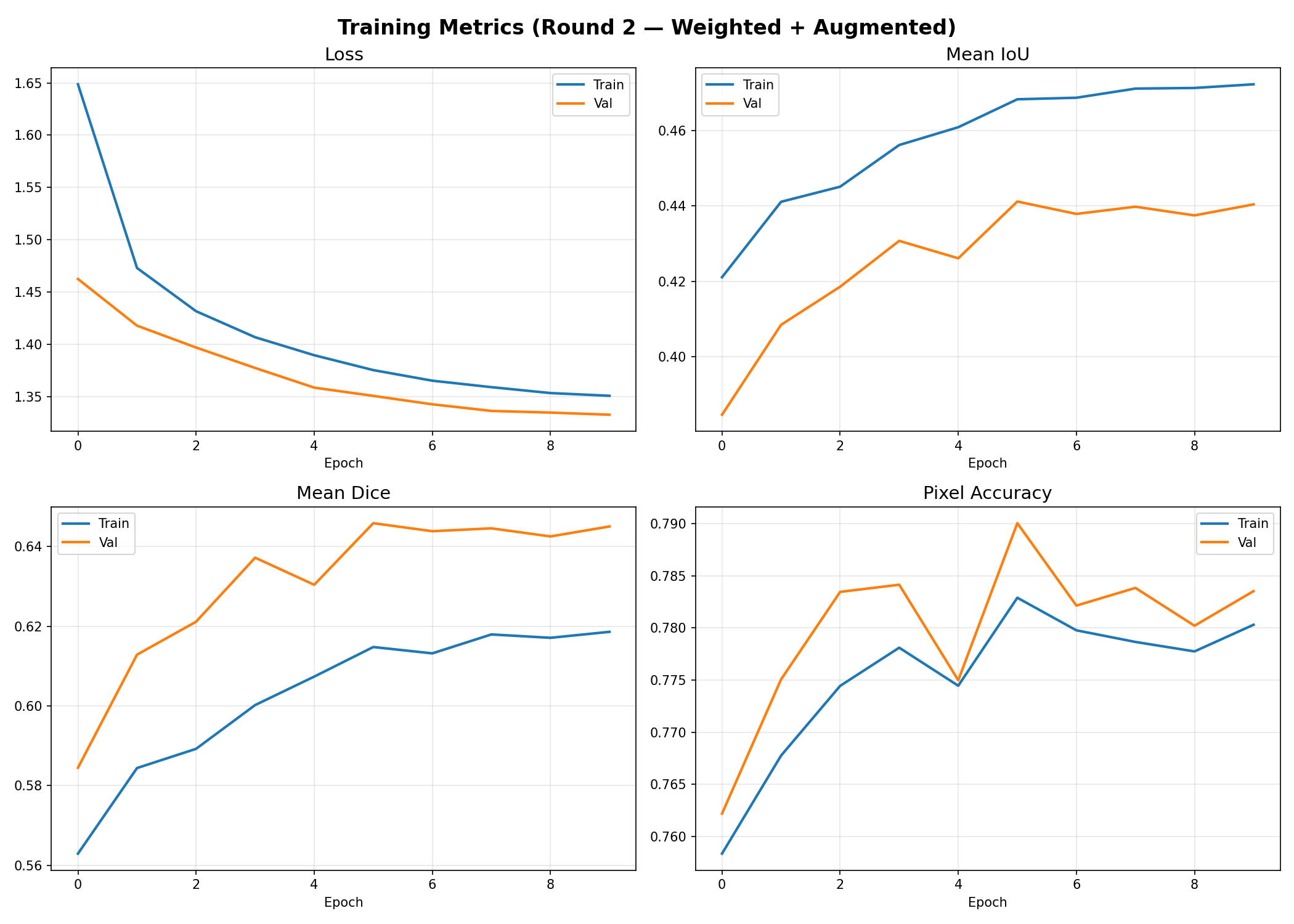
📊 Round 2 — Training Plots
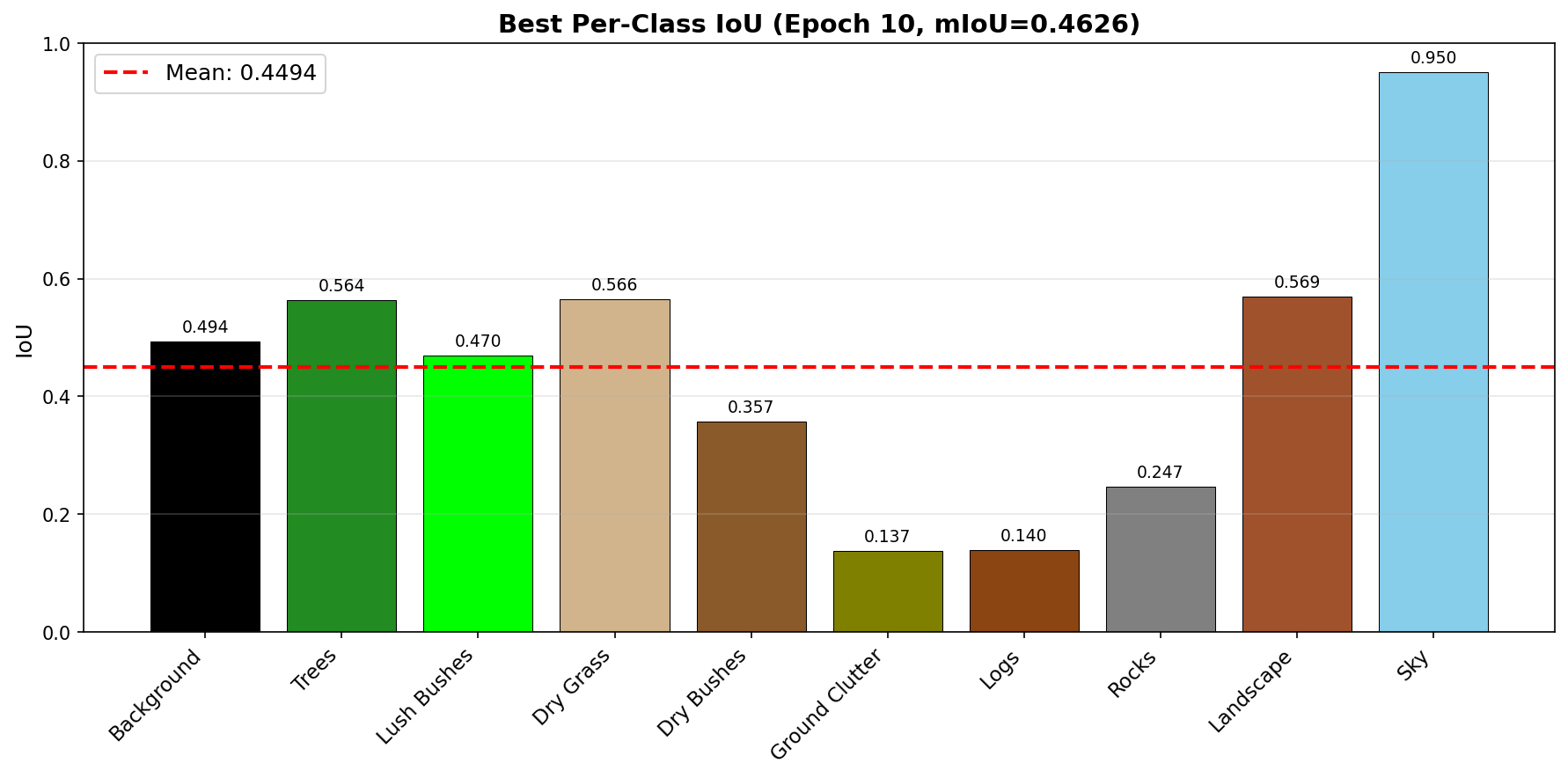
📊 Round 1 — Per-Class IoU
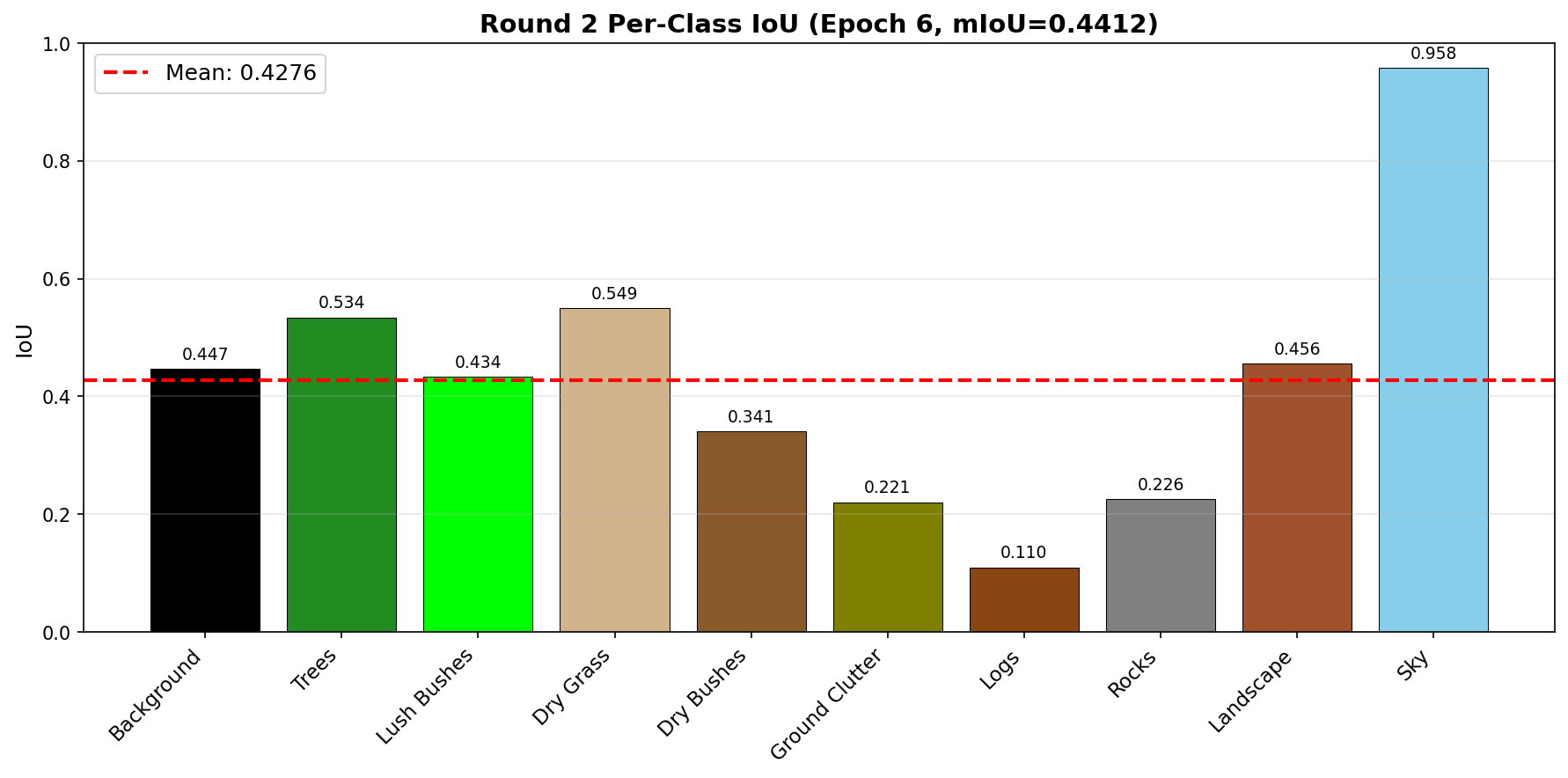
📊 Round 2 — Per-Class IoU
Class Performance Breakdown (Best Round)
Analysis
Failure Case Analysis
Understanding where and why the model struggles — key to iterative improvement.